
In this article of the series, we will see how to run models using LibTorch, how to use it for inference. In the first article of the series, while explaining usage scenarios, I mentioned that you can use a model trained in Python for inference in C++ and overcome some bottlenecks. Now we will train a model in Python (to not waste time, I will use a pre-trained model), save it, load it in C++ and perform inference.
First, let’s assume we trained a model in Python and the model is held in the resnet152 object. As I said, I will use a pre-trained model directly:
import torchvision.models as models
import torch
resnet152 = models.resnet152(pretrained=True)
script = torch.jit.script(resnet152)
traced = torch.jit.trace(resnet152, torch.rand(1, 3, 224, 224)) #Sample input must be provided for traced model.
script.save("./model_zoo/resnet152_sc.pt")
traced.save("./model_zoo/resnet152_tr.pt")
Here, let’s save the model using torch’s jit module in both script mode and trace mode. If you are not familiar with the use of the jit module in the Python API, I recommend taking a short break and reading the documentation. The reason I save both is that I will use them for comparison later. Now let’s quickly perform inference in C++ using the saved models:
#include <torch/script.h>
#include <iostream>
int main(int argc, const char* argv[]) {
if (argc != 2) {
std::cerr << "Usage: infer <path-to-exported-script-module>\n";
return -1;
}
at::globalContext().setBenchmarkCuDNN(1);
torch::jit::script::Module module;
try {
// Deserialize the ScriptModule from a file.
module = torch::jit::load(argv[1]);
std::cout << "Module loaded successfully.\n";
module.eval();
} catch (const c10::Error& e) {
std::cerr << "Error loading the model.\n";
return -1;
}
//RESNET input shape (BATCH_SIZE, 3, 224, 224)
const int BATCH_SIZE = 8, CHANNELS = 3, HEIGHT = 224, WIDTH = 224;
torch::NoGradGuard no_grad;
// Create a vector of inputs.
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(torch::ones({BATCH_SIZE, CHANNELS, HEIGHT, WIDTH}));
// Execute the model and turn its output into a tensor.
auto output = module.forward(inputs).toTensor();
for (int i = 0; i < BATCH_SIZE; ++i) {
std::cout << i << "th element class: " << torch::argmax(output.data()[i]).item<long>() << "\n";
}
return 0;
}
Let’s compile and run this code, then examine the code:
$ ./infer ./model_zoo/resnet152_sc.pt
Module loaded successfully.
Class of 0th element: 600
Class of 1th element: 600
Class of 2th element: 600
Class of 3th element: 600
Class of 4th element: 600
If we examine the code from the beginning, first we include the torch/script.h header file in our code. Then we create an instance of the torch::jit::script::Module class. This is actually the torch.nn.Module class we use in Python. As a result, it carries the model object and allows us to use the features provided by the Python API:
torch::jit::script::Module module;
Then we read the models we saved earlier in Python from the file and transfer them to this object. We take the saved model as an argument from the command line and read the model using error catching mechanism:
try {
// Deserialize the ScriptModule from a file.
module = torch::jit::load(argv[1]);
std::cout << "Module loaded successfully.\n";
}
catch (const c10::Error& e) {
std::cerr << "Error loading the model.\n";
return -1;
}
Here we use the model to run on CPU. If you want to use GPU, it is sufficient to add the following code to the line after you load the model:
module.to(at::kCUDA);
We will prepare the vector we need to feed our inputs to the model. The forward function of the torch::jit::script::Module class expects a vector of type std::vector<torch::jit::IValue>. I would like to remind that since the function uses the vector argument with std::move() move semantics, it aims to keep memory usage and speed loss at the lowest possible level:
std::vector<torch::jit::IValue> inputs;
inputs.push_back(torch::ones({BATCH_SIZE, CHANNELS, HEIGHT, WIDTH}));
//for GPU tensors:
//inputs.push_back(torch::ones({BATCH_SIZE, CHANNELS, HEIGHT, WIDTH}).to(at::kCUDA));
torch::jit::IValue is defined as a class. As an abbreviation of Interpreter Value, the IValue class wraps all basic types supported by the TorchScript interpreter. The IValue class is used for inputs and outputs of models. Although the interface of this class is quite wide, you can look below for its two basic functions:
/// // Make the IValue
torch::IValue my_ivalue(26);
std::cout << my_ivalue << "\n";
///
/// // Unwrap the IValue
int64_t my_int = my_ivalue.toInt() //toX() instead of X use appropriate data type for wrapped data.
std::cout << my_int << "\n";
If we come to why such a class is needed at this point, the types provided by LibTorch are different from the basic types provided by C++. It helps to ensure compatibility between Python API and C++ API, thus facilitating learning/using/getting used to.
Finally, we feed the inputs to the model and print the most probable class for each element in the batch to the standard output:
auto output = module.forward(inputs).toTensor();
for (int i = 0; i < BATCH_SIZE; ++i) {
std::cout << "Class of " << i << "th element: " << torch::argmax(output.data()[i]).item<long>() << "\n";
}
At this point, it would be beneficial to make a comparison. For this, we will compare the times to read and run the model saved in CPU and GPU for different batch sizes without using the jit module in Python, in script and trace modes (all tests were run 10 times and the time was calculated as average). First, let’s look at the sizes of the saved model files. We can say that there is no significant difference between file sizes:
| Module Type | File Size |
|---|---|
| torch.nn.Module | 241.6 MB |
| torch.jit.script | 242 MB |
| torch.jit.trace | 242.2 MB |
Now let’s look at the time it takes to read the model file from disk and make the model executable on CPU. As seen, we can read much faster in C++ first:
| CPU Read Time (ms) | Python | C++ |
|---|---|---|
| Script | 0.985 | 0.449 |
| Trace | 0.912 | 0.356 |
Now let’s look at the time it takes to read the model file and make it executable on GPU. Although the speed difference decreases, C++ still reads and makes the model executable faster:
| GPU Read Time (ms) | Python | C++ |
|---|---|---|
| Script | 2.286 | 2.137 |
| Trace | 2.214 | 2.025 |
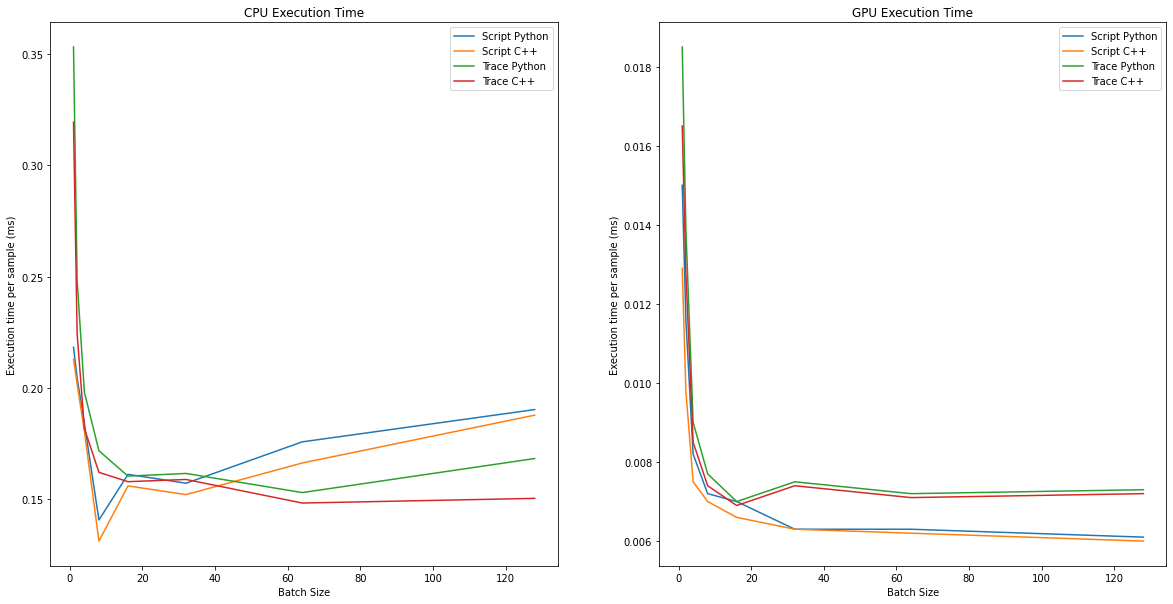
Now let’s examine the batch processing times. In the chart on the left, CPU, on the right, GPU shows the inference times of the model for different batch sizes for one sample. In 95% of the test cases, C++ API runs faster at varying rates. On CPU, models saved in script mode generally ran faster, on GPU side, models saved in trace mode ran faster. Single thread was used in these calculations:
As a result, I think you have seen that running models using C++ API is not troublesome at all. In fact, developing a model from scratch on C++ is not very difficult. I will try to explain this in the following articles. But I think it would be better to examine how to deal with data first. In the next article, I will explain how to read data (image, video, csv, text, etc.) and how to provide this data to LibTorch during inference and training.
Other articles in the series: